🎉 It’s here! We’re happy to introduce the January 2024 Snikket Server release.
This is the core software of the Snikket project - a self-hostable “personal
messaging server in a box”. If you wish for something like Messenger, WhatsApp
or Signal, but not using their servers, Snikket is for you. Once deployed, you
can create invitation links for family, friends, colleagues… any kind of
social group is a good fit for Snikket. The invitation links walk people through
downloading the
Snikket app
and joining
your private Snikket instance.
What’s new in this release?
Changes to Circles
While Snikket is designed for groups of people to easily communicate with each
other, we know that often people have multiple social groups. Our
Circles
feature allows the admin of the Snikket instance to decide which people will
see each other within the Snikket apps, by grouping them into “circles”. For
example, you could use this to separate your family from your friends, even
within the same Snikket instance.
In previous releases, the Snikket server automatically created a group chat,
and added everyone in the circle to that chat automatically. We received a lot
of feedback that these chats were either not really used, or sometimes
confusing (for example, because they are managed automatically by the server
and you cannot manage them yourself within the Snikket app). Other people
liked the group chats, but wished that more than one could be made!
In this new release, creating a circle will no longer create a group chat
automatically. However you can also now create as many “circle chats” as you
want, and give them individual names. This can be useful for creating
per-topic chats for all members of a circle.
Of course if you just want normal private group chats, you can still create
those within the Snikket app as usual, and manage the group yourself.
Last activity display
Sometimes people drop off Snikket, intentionally or unintentionally. For
example, if they get a new phone and forget to reinstall the app or have
problems connecting. In the web interface you can now see when the user
was last active.
You can use this information to clean up unused accounts, or reach out to
people who might need help regaining access to their account.
Connectivity and security
We have made a number of connectivity improvements. Snikket now enables IPv6
by default (previously it had to be enabled manually). If you don’t have IPv6,
that’s fine… thanks to new changes we have made, Snikket will now adapt
automatically to network conditions and connect using the best method that
works. We expect IPv6-only networks to become increasingly common in the years
ahead, so if your server is not currently set up for IPv6, consider doing
that.
The new release now also supports DNSSEC and DANE 🔒, both of these are used to
improve connection security. Currently these are disabled by default, however,
because Snikket does not know if your system’s DNS resolver actually supports
DNSSEC. We may enable it automatically in future releases if Snikket can
determine that reliably. For now,
it’s opt-in
.
Faster and stronger authentication
We’ve also been working on optimizing and strengthening app-to-server
authentication. A lot of this work was funded by NGI0+NLnet and is available
in our sister project, Prosody. You can read more details in the blog post
Bringing FASTer authentication to Prosody and XMPP
.
Snikket already supported a neat security measure called “channel binding”,
but it previously only worked over TLS 1.2 connections. TLS 1.3 usage has
increased rapidly in recent years, and we now support channel binding on
TLS 1.3 connections too. Channel binding prevents
machine-in-the-middle attacks
if the TLS certificate is compromised somehow.
All these features help protect against certain kinds of attack that were
deemed unlikely
until recently
.
Dropping older security protocols
Mainly for compatibility reasons, Snikket previously supported an
authentication mechanism where the client sends the user’s password to the
server, but only over TLS-encrypted connections. This is how almost all
website login forms work today, from your webmail to your online banking.
However the Snikket apps actually use a
more secure login method
,
which has many additional security features that you won’t find on most other
online services.
Prioritizing security over compatibility, we have decided to disable less
secure mechanisms entirely. If you use your Snikket account with third-party
XMPP apps, bots or utilities that are not up to date with modern best
practices, this may affect you.
Similarly, we have again reviewed and updated the TLS versions and ciphers
that Snikket supports, in line with
Mozilla’s recommendations
,
as we do in every release. This change also has the potential to affect
connectivity from some very old apps and devices.
Easy account restoration
The Snikket apps, as well as many third-party apps, allow people to delete
their Snikket account from within the app.
However, as the number of Snikket users has grown, so have reports from people
who accidentally deleted their account! This can be due to confusion - e.g.
intending to remove the account from the app, rather than removing it from the
server. A number of these cases were due to confusing or buggy third-party
apps. It doesn’t happen very often, but it was happening too often.
Of course, deleted accounts can be restored from backups (which you have, of
course 😇) - but it was a complex time-consuming process to selectively
restore a single account without rolling back everyone else’s data.
In this release, when a request is received from an app to delete a user’s
account, the server will lock the account and schedule its deletion in 7 days
(or whatever the server’s data retention time is set to). During this time,
the account can be restored easily from the web interface if it turns out to
have been a mistake.
Farewell to the welcome message
In previous releases, new accounts would receive an auto-generated “welcome
message” from the server. This had a
number of issues
,
and we have decided to remove it for now. Instead we will work on integrating
any “welcome” functionality directly into the apps.
Languages and translations
Many languages received updates in this release, including French, German,
Indonesian, Polish, Italian and Swedish.
We added support for two additional languages: Russian and Ukranian.
Many thanks to all translators for their help with this effort!
Our last major release was made just weeks before the Russian invasion of
Ukraine shocked the world. We would like to take this opportunity to bring to
mind that this sad situation is ongoing. It directly affects some of the
contributors and users of our project, and many individuals, families and
communities. Please consider what you can do to help them.
Other changes
We only listed a handful of the main features here. The reality is that
beneath the hood, we have made a large number of changes to improve security,
performance and reliability. And we have in place the foundations for other
exciting things we have in the pipeline!
Installing and upgrading
Choose your adventure:
-
If you’re new to Snikket, you can head straight to the
setup guide
for instructions on how to get started.
-
To upgrade an existing self-hosted instance to the new release, read the
upgrading guide
.
-
Customers on our hosting platform can expect the new release to be rolled out
soon, we’ll be in touch! If you have any questions, you can
contact support
.
Happy chatting!
P.S. If you’re planning to be at FOSDEM in a few weeks, we’ll be there, come
and say hi! We’d love to meet you :)

chevron_right









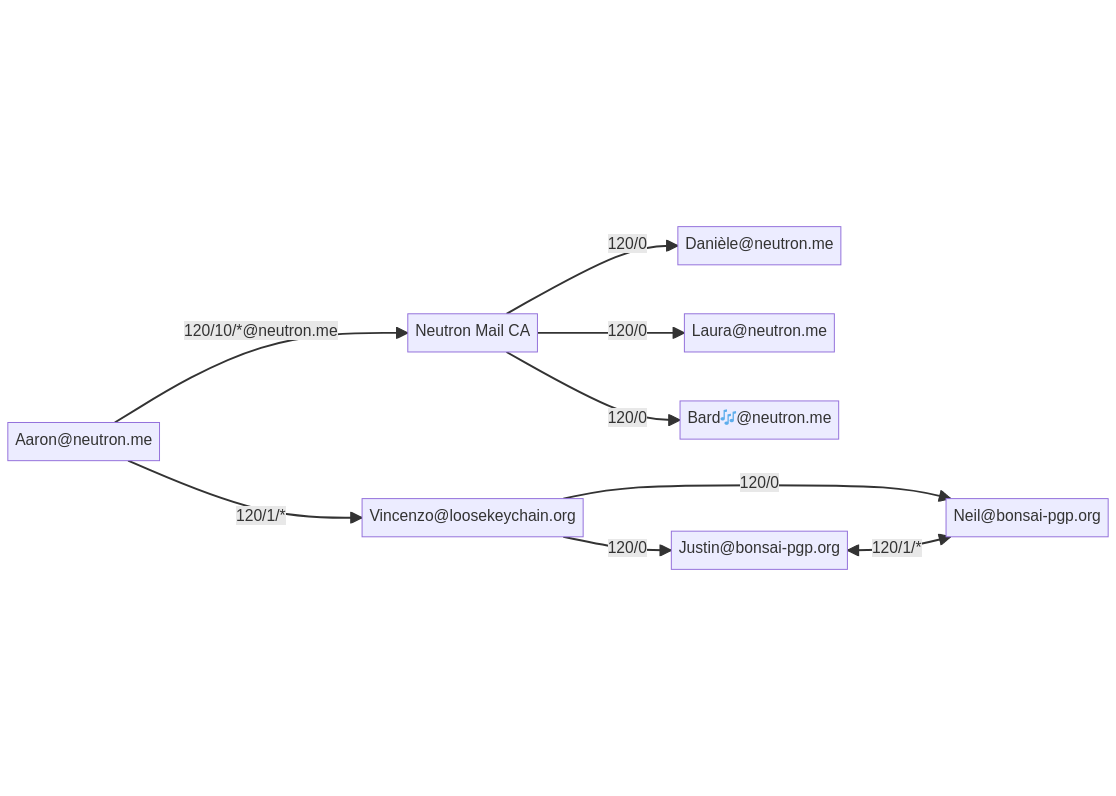 An example for an OpenPGP Web-of-Trust. Simply by delegating trust to the Neutron Mail CA and to Vincenzo, Aaron is able to authenticate a number of certificates.
An example for an OpenPGP Web-of-Trust. Simply by delegating trust to the Neutron Mail CA and to Vincenzo, Aaron is able to authenticate a number of certificates.