-
chevron_right
Pirating “The Pirate Bay” TV Series is Ironically Difficult (Updated)
news.movim.eu / TorrentFreak · Sunday, 10 November, 2024 - 08:52 · 3 minutes
 The inception and early years of The Pirate Bay are
an intriguing chapter
of the Internet’s history.
The inception and early years of The Pirate Bay are
an intriguing chapter
of the Internet’s history.
Founded by the Piratbyrån group, The Pirate Bay and its founders embraced the power of the new BitTorrent technology: to copy culture en masse .
By doing so, they altered the public discourse, openly taunting the entertainment industries in the process.
This chapter didn’t end as planned for the lead characters; Fredrik Neij (TiAMO), Peter Sunde (Brokep), and Gotffrid Svartholm (Anakata), who were eventually sentenced to prison . By then, however, they had sparked a digital and political revolution, the impact of which is still felt today.
TV Series
The Pirate Bay didn’t just trigger a file-sharing bonanza, it was exemplary for the rapid rise of the web. New technology empowered people whose lives were traditionally dictated by mainstream entertainment and publishing companies.
The web created new forms to share news, opinions, knowledge, and media. And few Swedes with keyboards had the power to upset billion-dollar companies.
It doesn’t take a genius to realize that this is a good story, perhaps even a movie script? This includes the people at the Swedish production company B-Reel Films, who got the green light to turn it into a TV series a few years ago.
The series premiered at the on-demand platform of the Swedish national broadcaster SVT a few hours ago. International deals haven’t been announced, but pirates can generally get access anyway.
Pirating ‘The Pirate Bay’ Series
Soon after the first two episodes of The Pirate Bay series came out, scene release copies started circulating online . As one would expect.
The Scene group OLLONBORRE, which specializes in Swedish content, was the first to pick the show up. Within minutes, the first 1080p WEB-rips were posted on private scene servers and 720p copies followed a few hours later.

Interestingly, pirate releases have yet to make their way to The Pirate Bay. We haven’t seen any other copies on other public pirate sites either, which is surprising given the topic of the series.
Update November 10 : After a delay, the episodes eventually were published on TPB and other pirate sites.
It’s common knowledge that The Scene – a secretive network of release groups – prefers to keep its releases private. Therefore, it wasn’t happy with The Pirate Bay’s public nature and rise to prominence in the early 2003s, which is highlighted in the first episodes of the TV series.
However, we expected non-scene release groups would be eager to pick up the show. Apparently that’s not the case, yet.
Fact-Based Fiction
While the broader international audience must wait for the officially sanctioned release, we can add a disclaimer for future viewers. While entertaining and engaging, the series should not be taken as fact.
The script is loosely based on The Pirate Bay story and many of the scenes are fiction. New elements were added, timelines have been changed, and the characters are constructed by the show’s writers, which is not necessarily how they came across in real life.
The Pirate Bay’s founders didn’t participate in the production , which means that the creators had no other option than to fill in some blanks.
In an interview with Drama Quarterly , director Jens Sjögren previously acknowledged that they had to mix facts and fiction to tell the story. He understands that some people won’t like that.
“People are going to say a lot of shit about it. ‘It was not exactly like this, blah, blah, blah.’ No, but we really broke our fucking backs to try to just embrace the feeling of really struggling with something you believe in so hard – so much so you would almost be ready to go to prison for it,” Sjögren said.
It wasn’t the creators’ main goal to create a literal replay of what happened. Instead, Sjögren said that he tried to capture the spirit of The Pirate Bay founders’ ambitions and goals.
Whether this succeeded is up to the viewer, but the series definitely shows the contrasting personalities of Fredrik, Gottfrid, and Peter. They were all in it for different reasons, which may be part of their initial success.
—
This weekend we will publish a follow-up article, sharing some thoughts on the series with input from Pirate Bay co-founder Peter Sunde and Piratbyrån co-founder Rasmus Fleischer.
From: TF , for the latest news on copyright battles, piracy and more.
 The “Infringing Website List” (IWL) was launched in March 2014 as part of the Police Intellectual Property Crime Unit’s (PIPCU) efforts to combat intellectual property crime.
The “Infringing Website List” (IWL) was launched in March 2014 as part of the Police Intellectual Property Crime Unit’s (PIPCU) efforts to combat intellectual property crime.





 App stores are littered with apps that promise free access to music, but only a few live up to expectations.
App stores are littered with apps that promise free access to music, but only a few live up to expectations.

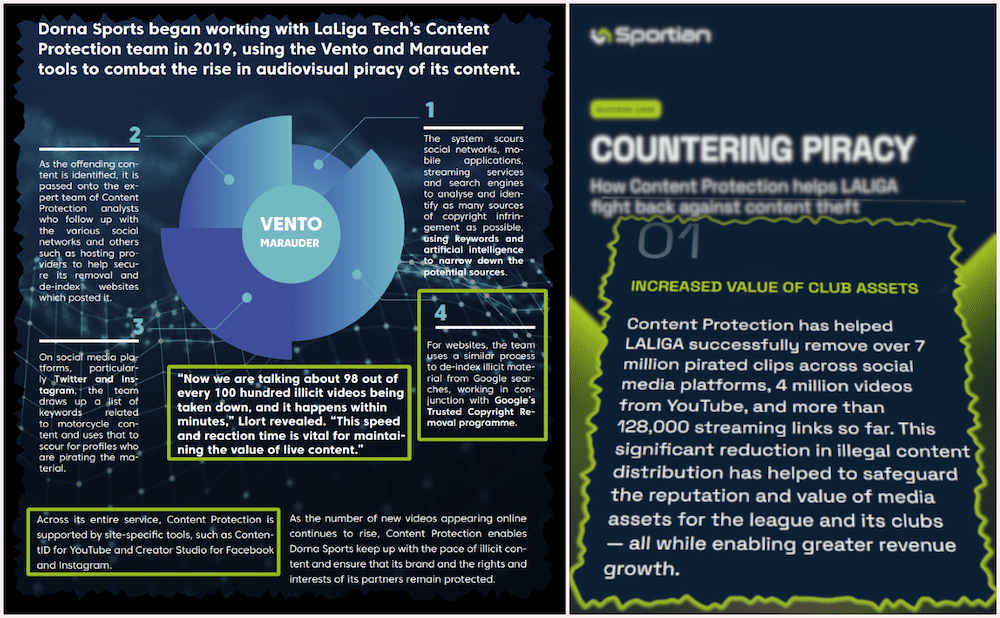
 Library Genesis, often shortened to
Library Genesis, often shortened to




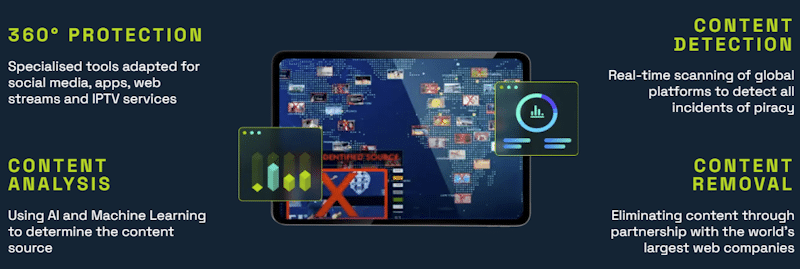

 The
The