Adopting
machine learning for business
is necessary for companies that want to sharpen their competitive industries. With the global market for machine learning projected to reach an impressive
$210 billion by 2030
, businesses are keen to seek active solutions that streamline processes and improve customer interactions.
While organisations may already employ some form of data analysis, traditional methods can need more sophistication to address the complexities of today’s market. Businesses that consider optimising machines unlock valuable data insights, make accurate predictions and deliver personalised experiences that truly resonate with customers, ultimately driving growth and efficiency.
What is Machine Learning?
Machine learning (ML) is a subset of artificial intelligence (AI). It uses
machine learning algorithms
, designed to learn from data, identify patterns, and make predictions or decisions, without explicit programming. By analysing patterns in the data, a machine learning algorithm identifies key features that define a particular data point, allowing it to apply this knowledge to new, unseen information.
Fundamentally data-driven, machine learning relies on vast information to learn, adapt, and improve over time. Its predictive capabilities allow models to forecast future outcomes based on the patterns they uncover. These models are generalisable, so they can apply insights from existing data to make decisions or predictions in unfamiliar situations.
You can read more about machine learning and AI in
our previous post
.
Approaches to Machine Learning
Machine learning for business typically involves two key approaches:
supervised and unsupervised learning
, each suited to different types of problems. Below, we explain each approach and provide examples of
machine learning use cases
where these techniques are applied effectively.
-
Supervised Machine Learning:
This approach demands labelled data, where the input is matched with the correct output. The algorithms learn to map inputs to outputs based on this training set, honing their accuracy over time.
-
Unsupervised Machine Learning:
In contrast, unsupervised learning tackles unlabelled data, compelling the algorithm to uncover patterns and structures independently. This method can involve tasks like clustering and dimensionality reduction. While unsupervised techniques are powerful, interpreting their results can be tricky, leading to challenges in assessing whether the model is truly on the right track.
Example of Supervised vs unsupervised learning
Supervised learning
uses historical data to make predictions, helping businesses optimise performance based on past outcomes. For example, a retailer might use supervised learning to predict
customer churn
. By feeding the algorithm data such as customer purchase history and engagement metrics, it learns to identify patterns that indicate a high risk of churn, allowing the business to implement proactive retention strategies.
Unsupervised learning
, on the other hand, uncovers hidden patterns within data. It is particularly useful for discovering new customer segments without prior labels. For instance, an e-commerce platform might use unsupervised learning to group customers by their browsing habits, discovering niche audiences that were previously overlooked.
The Impact of Machine Learning on Business
A recent survey by McKinsey revealed that
56% of organisations
surveyed are using machine learning in at least one business function to optimise their operations. This growing trend shows how machine learning for business is becoming integral to staying competitive.
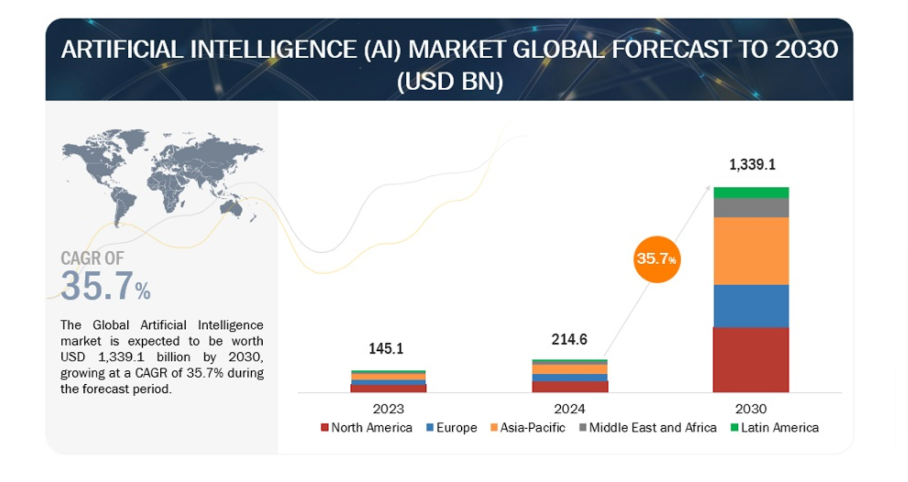
The AI market as a whole is also on an impressive growth trajectory, projected to reach
USD 407.0 billion by 2027
.
AI Global Market Forecast to 2030
We’re expected to see an astounding compound growth rate (CAGR) of
35.7%
by 2030, proving that business analytics is no longer just a trend; it’s moving into a core component of modern enterprises.
Machine Learning for Business Use Cases
Machine learning can be used in numerous ways across industries to enhance workflows. From
image recognition
to
fraud detection
, businesses are actively using AI to streamline operations.
Image Recognition
Image recognition, or image classification is a powerful machine learning technique used to identify and classify objects or features in digital images.
Artificial intelligence (AI) and machine learning (ML) are revolutionising image recognition systems by uncovering hidden patterns in images that may not be visible to the human eye. This technology allows these systems to make independent and informed decisions, significantly reducing the reliance on human input and feedback.
As a result, visual data streams can be processed automatically at an ever-increasing scale, streamlining operations and enhancing efficiency. By harnessing the power of AI, businesses can leverage these insights to improve their decision-making processes and gain a competitive edge in their respective markets.
It plays a crucial role in tasks like pattern recognition, face detection, and facial recognition, making it indispensable in security and social media sectors.
Fraud Detection
With financial institutions handling millions of transactions daily, distinguishing between legitimate and fraudulent activity can be a challenge. As online banking and cashless payments grow, so too has the volume of fraud. A 2023 report from TransUnion revealed a
122% increase in digital fraud
attempts in the US between 2019 and 2022.
Machine learning helps businesses by flagging suspicious transactions in real-time, with companies like Mastercard using AI to predict and prevent fraud before it occurs, protecting consumers from potential theft.
Speech Recognition
Voice commands have become a common feature in smart devices, from setting timers to searching for shows.
Thanks to machine learning, devices like Google Nest speakers and Amazon Blink security systems can recognise and act on voice inputs, making hands-free operation more convenient for users in everyday situations.
Improved Healthcare
Machine learning in healthcare
has led to major improvements in patient care and medical discoveries. By analysing vast amounts of healthcare data, machine learning enhances the accuracy of diagnoses, optimises treatments, and accelerates research outcomes.
For instance, AI systems are already employed in radiology to detect diseases in medical images, such as identifying cancerous growths. Additionally, machine learning is playing a crucial role in
genomic research
by uncovering patterns linked to genetic disorders and potential therapies. These advancements are paving the way for improved diagnostics and faster medical research, offering tremendous potential for the future of healthcare.
Key applications of machine learning in healthcare include:
-
Developing predictive modelling
-
Improving diagnostic accuracy
-
Personalising patient care
-
Automating clinical workflows
-
Enhancing patient interaction
Machine learning in healthcare utilises algorithms and statistical models to analyse large medical datasets, facilitating better decision-making and personalised care. As a subset of AI, machine learning identifies patterns, makes predictions, and continuously improves by learning from data. Different types of learning, including supervised and unsupervised learning, find applications in disease classification and personalised treatment recommendations.
Chatbots
Many businesses rely on customer support to maintain satisfaction. However, staffing trained specialists can be expensive and inefficient. AI-powered chatbots, equipped with natural language processing (NLP), assist by handling basic customer queries. This frees up human agents to focus on more complicated issues. Companies can provide more efficient and effective support without overburdening their teams.
Each of these applications offers businesses the chance to streamline operations and improve customer experiences.
Machine Learning Case Studies
Machine learning for business is transforming industries by enabling companies to enhance their operations, improve customer experiences, and drive innovation.
Here are a few
machine learning case studies
showing how leading organisations have integrated machine learning into their business strategies.
PayPal
PayPal, a worldwide payment platform, faced huge challenges in identifying and preventing fraudulent transactions.
To tackle this issue, the company implemented machine learning algorithms designed for
fraud detection
. These algorithms analyse various aspects of each transaction, including the transaction location, the device used, and the user’s historical behaviour. This approach has significantly enhanced PayPal’s ability to protect users and maintain the integrity of its payment platform.
YouTube
YouTube has long employed machine learning to optimise its operations, particularly through its
recommendation algorithms
. By analysing vast amounts of historical data, YouTube suggests videos to its viewers based on their preferences. Currently, the platform processes over 80 billion data points for each user, requiring large-scale neural networks that have been in use since 2008 to effectively manage this immense dataset.
Dell
Recognising the importance of data in marketing, Dell’s marketing team sought a data-driven solution to enhance response rates and understand the effectiveness of various words and phrases. Dell partnered with Persado, a firm that leverages AI to create compelling marketing content. This collab led to an overhaul of Dell’s email marketing strategy, resulting in a 22% average increase in page visits and a 50% boost in click-through rates (CTR). Dell now utilises machine learning methods to refine its marketing strategies across emails, banners, direct mail, Facebook ads, and radio content.
Tesla
Tesla employs machine learning to enhance the performance and features of its electric vehicles. A key application is its
Autopilot system
, which combines cameras, sensors, and machine learning algorithms to provide advanced driver assistance features such as lane centring, adaptive cruise control, and automatic emergency braking.
The Autopilot system uses deep neural networks to process vast amounts of real-world driving data, enabling it to predict driving behaviour and identify potential hazards. Additionally, Tesla leverages machine learning in its battery management systems to optimise battery performance and longevity by predicting behaviour under various conditions.
Netflix
Netflix is a leader in personalised content recommendations. It uses machine learning to analyse user viewing habits and suggest shows and movies tailored to individual preferences. This feature has proven essential for improving customer satisfaction and increasing subscription renewals. To develop this system, Netflix utilises viewing data—including viewing durations, metadata, release dates, timestamps etc. Netflix then employs collaborative filtering, matrix factorisation, and deep learning techniques to accurately predict user preferences.
Benefits of Machine Learning in Business
If you’re still contemplating the value of machine learning for your business, consider the following key benefits:
|
Automation Across Business Processes
|
Machine learning automates key business functions, from marketing to manufacturing, boosting yield by up to 30%, reducing scrap, and cutting testing costs. This frees employees from more creative, strategic tasks.
|
Efficient Predictive Maintenance
|
ML helps manufacturing predict equipment failures, reducing downtime and extending machinery lifespan, ensuring operational continuity.
|
|
Enhanced Customer Experience and Accurate Sales Forecasts
|
Retailers use machine learning to analyse consumer behaviour, accurately forecast demand, and personalise offers, greatly improving customer experience.
|
|
Data-Driven Decision-Making
|
ML algorithms quickly extract insights from data, enabling faster, more informed decision-making and helping businesses develop effective strategies.
|
|
Error Reduction
|
By automating tasks, machine learning reduces human error, so employees to focus on complex tasks, significantly minimising mistakes.
|
|
Increased Operational Efficiency
|
Automation and error reduction from ML lead to efficiency gains. AI systems like chatbots boost productivity by up to 54%, operating 24/7 without fatigue.
|
|
Enhanced Decision-Making
|
ML processes large data sets swiftly, turning information into objective, data-driven decisions, removing human bias and improving trend analysis.
|
|
Addressing Complex Business Issues
|
Machine learning tackles complex challenges by streamlining operations and boosting performance, enhancing productivity and scalability.
|
As organisations increasingly adopt machine learning, they position themselves to not only meet current demands but poise them for future innovation.
Elixir and Erlang in Machine Learning
As organisations explore machine learning tools, many are turning to Erlang and Elixir programming languages to develop customised solutions that cater to their needs. Erlang’s fault tolerance and scalability make it ideal for AI applications, as described in our blog on
adopting AI and machine learning for business
. Additionally, Elixir’s concurrency features and simplicity enable businesses to build high-performance AI applications.
Learn more about
how to build a machine-learning project in Elixir here
.
As organisations become more familiar with AI and machine learning tools, many are turning to
Erlang
and
Elixir programming languages
to develop customised solutions that cater to their needs.
Elixir, built on the Erlang virtual machine (BEAM), delivers top concurrency and low latency. Designed for real-time, distributed systems, Erlang prioritises fault tolerance and scalability, and Elixir builds on this foundation with a high-level, functional programming approach. By using pure functions and immutable data, Elixir reduces complexity and minimises unexpected behaviours in code. It excels at handling multiple tasks simultaneously, making it ideal for AI applications that need to process large amounts of data without compromising performance.
Elixir’s simplicity in problem-solving also aligns perfectly with AI development, where reliable and straightforward algorithms are essential for machine learning. Furthermore, its distribution features make deploying AI applications across multiple machines easier, meeting the high computational demands of AI systems.
With a rich ecosystem of libraries and tools, Elixir streamlines development, so AI applications are scalable, efficient, and reliable. As AI and machine learning become increasingly vital to business success, creating high-performing solutions will become a key competitive advantage.
Final Thoughts
Embracing machine learning for business is no longer optional for companies that want to remain competitive. Machine learning tools empower businesses to make faster, data-driven decisions, streamline operations, and offer personalised customer experiences.
Contact the Erlang Solutions team today
if you’d like to discuss building AI systems using Elixir and Erlang or for more insights into implementing machine learning solutions,
The post
Why you should consider machine learning for business
appeared first on
Erlang Solutions
.

chevron_right