

-
 chevron_right
chevron_right
Erlang Solutions: Cómo depurar tu RabbitMQ
news.movim.eu / PlanetJabber • 29 March, 2023 • 14 minutes

Descubre las herramientas y métodos adecuados para la depuración de RabbitMQ.
Lo que aprenderás en este blog.
Nuestros clientes de consultoría de RabbitMQ provienen de una amplia gama de industrias. Como resultado, hemos visto casi todos los comportamientos inesperados que puede presentar. RabbitMQ es un software complejo que emplea concurrencia y cómputo distribuido (a través de Erlang), por lo que depurarlo no siempre es sencillo. Para llegar a la causa raíz de un comportamiento inesperado (y no deseado), necesitas las herramientas adecuadas y la metodología adecuada. En este artículo, demostraremos ambas para ayudarte a aprender la técnica de depuración en RabbitMQ.
El problema de depurar RabbitMQ.
La inspiración para este blog proviene de un ejemplo real. Uno de nuestros clientes tenía la API HTTP de administración de RabbitMQ proporcionando información crucial a su sistema. El sistema dependía mucho de la API, específicamente del endpoint /api/queues porque el sistema necesitaba saber el número de mensajes listos en cada cola en un clúster de RabbitMQ. El problema era que a veces una solicitud HTTP al endpoint duraba hasta decenas de segundos (en el peor de los casos, ni siquiera podían obtener una respuesta de la API).
Entonces, ¿qué causó que algunas solicitudes tomaran tanto tiempo? Para responder a esa pregunta, intentamos reproducir el problema a través de pruebas de carga.
Ejecutando pruebas de carga.
Utilizamos una plataforma que creamos para MongooseIM para ejecutar nuestras Pruebas de Carga Continuas . Aquí están algunos de los aspectos más importantes de la plataforma:
- todos los servicios involucrados en una prueba de carga se ejecutan dentro de contenedores de docker
- la carga es generada por Amoc ; es una herramienta de código abierto escrita en Erlang para generar cargas masivamente paralelas de cualquier tipo (AMQP en nuestro caso)
- se recopilan métricas del sistema en prueba y del sitio de Amoc para un análisis posterior.
El diagrama a continuación representa una arquitectura lógica de una prueba de carga de ejemplo con RabbitMQ:
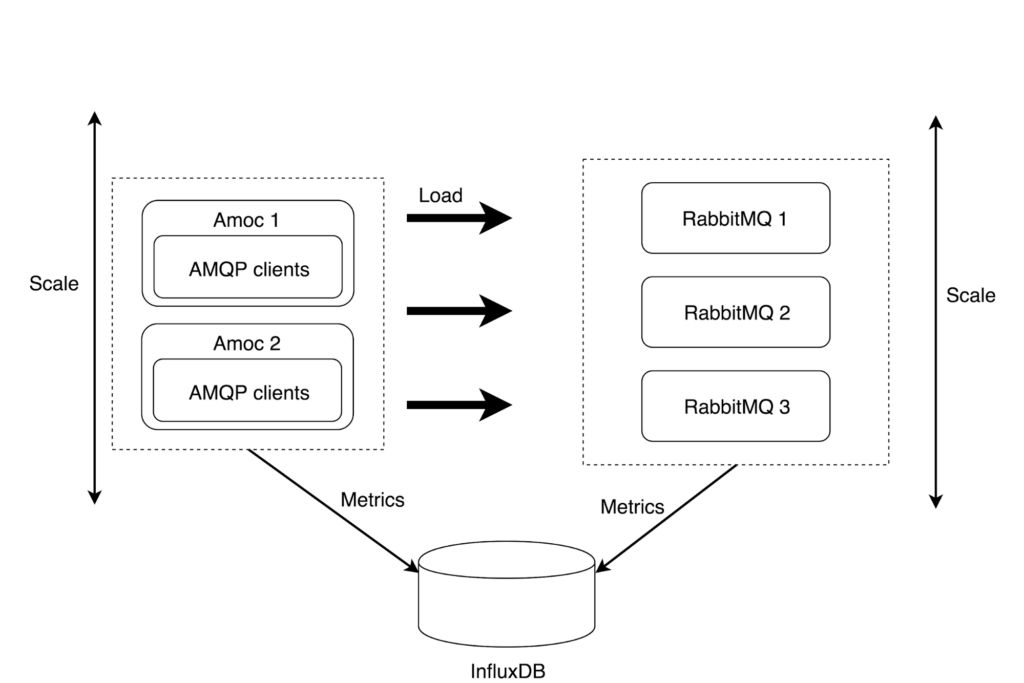
En el diagrama, el lado izquierdo muestra un clúster de nodos de Amoc que emulan clientes AMQP que, a su vez, generan la carga contra RabbitMQ. Por otro lado, podemos ver un clúster de RabbitMQ que sirve a los clientes AMQP. Todas las métricas de los servicios de Amoc y RabbitMQ se recopilan y almacenan en una base de datos InfluxDB.
Consultas lentas de Management HTTP API
Intentamos reproducir las consultas lentas a Management HTTP API en nuestras pruebas de carga. El escenario de prueba fue bastante sencillo. Un grupo de editores publicaba mensajes en el intercambio predeterminado. Los mensajes de cada editor se dirigían a una cola dedicada (cada editor tenía una cola dedicada). También había consumidores conectados a cada cola. La replicación de cola estaba habilitada.
Para valores concretos, consulte la tabla a continuación:
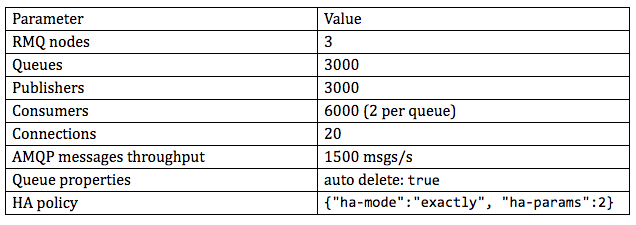
Esa configuración estresó los servidores Rabbit en nuestra infraestructura. Como se ve en los gráficos a continuación:
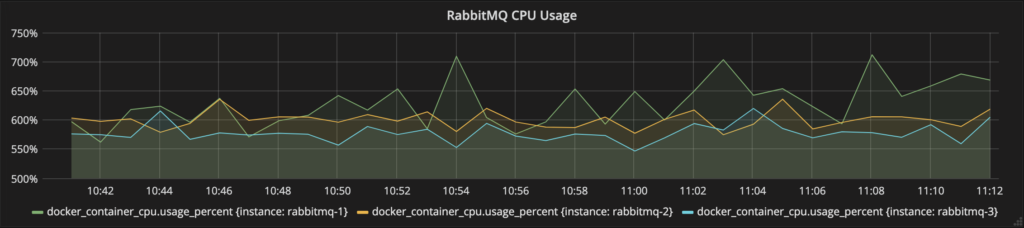
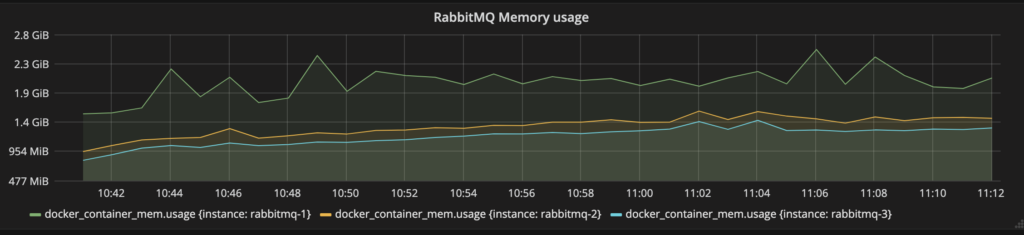
Cada nodo de RabbitMQ consumió alrededor de 6 (de 7) núcleos de CPU y aproximadamente 1,4 GB de RAM, excepto
rabbitmq-1
que consumió significativamente más que los otros. Eso se debió probablemente a que tuvo que atender más solicitudes de Management HTTP API que los otros dos nodos.
Durante la prueba de carga, se consultó el endpoint
/api/queues
cada dos segundos
para obtener la lista de todas las colas junto con los valores correspondientes de
messages_ready
. Una consulta se veía así:
http://rabbitmq-1:15672/api/queues?columns=name,messages_readyAquí están los resultados de la prueba:
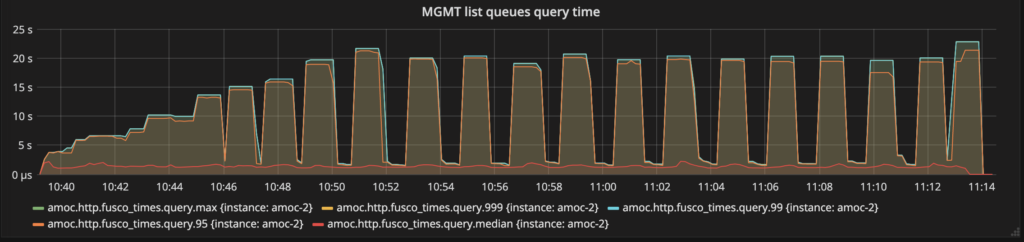
La figura anterior muestra el tiempo de consulta durante una prueba de carga. Está claro que las cosas son muy lentas. La mediana es de 1,5 segundos mientras que los percentiles 95, 99, 999 y máx. llegan a 20 segundos.
Debugging
Una vez confirmado el problema y puede reproducirse, estamos listos para comenzar a depurar. La primera idea fue encontrar la función Erlang que se llama cuando llega una solicitud a la API de administración HTTP de RabbitMQ y determinar dónde esa función pasa su tiempo de ejecución. Si pudiéramos hacer esto, nos permitiría localizar el código más costoso detrás de la API.
Encontrar la función de entrada
Para encontrar la función que estábamos buscando, tomamos los siguientes pasos:
- buscamos en el complemento de administración de RabbitMQ para encontrar la asignación adecuada de “ruta HTTP a función”,
- usamos la función de rastreo de Erlang para verificar si se llama a una función encontrada cuando llega una solicitud.
El complemento de administración utiliza cowboy (un servidor HTTP de Erlang) debajo para servir las solicitudes de API. Cada punto final de HTTP requiere un módulo de devolución de llamada de cowboy, por lo que encontramos fácilmente la función rabbit_mgmt_wm_queues:to_json/2 que parecía manejar las solicitudes que llegaban a /api/queues. Confirmamos eso con el rastreo (usando una biblioteca de recuperación que se envía con RabbitMQ por defecto).
root@rmq-test-rabbitmq-1:/rabbitmq_server-v3.7.9# erl -remsh rabbit@rmq-test-rabbitmq-1 -sname test2 -setcookie rabbit
Erlang/OTP 21 [erts-10.1] [source] [64-bit] [smp:22:7] [ds:22:7:10] [async-threads:1]
Eshell V10.1 (abort with ^G)
(rabbit@rmq-test-rabbitmq-1)1> recon_trace:calls({rabbit_mgmt_wm_queues, to_json, 2}, 1).
1
11:0:48.464423 <0.1294.15> rabbit_mgmt_wm_queues:to_json(#{bindings => #{},body_length => 0,cert => undefined,charset => undefined,
has_body => false,
headers =>
#{<<"accept">> => <<"*/*">>,
<<"authorization">> => <<"Basic Z3Vlc3Q6Z3Vlc3Q=">>,
<<"host">> => <<"10.100.10.140:53553">>,
<<"user-agent">> => <<"curl/7.54.0">>},
host => <<"10.100.10.140">>,host_info => undefined,
media_type => {<<"application">>,<<"json">>,[]},
method => <<"GET">>,path => <<"/api/queues">>,path_info => undefined,
peer => {{10,100,10,4},54136},
pid => <0.1293.15>,port => 53553,qs => <<"columns=name,messages_ready">>,
ref => rabbit_web_dispatch_sup_15672,
resp_headers =>
#{<<"content-security-policy">> => <<"default-src 'self'">>,
<<"content-type">> => [<<"application">>,<<"/">>,<<"json">>,<<>>],
<<"vary">> =>
[<<"accept">>,
[<<", ">>,<<"accept-encoding">>],
[<<", ">>,<<"origin">>]]},
scheme => <<"http">>,
sock => {{172,17,0,4},15672},
streamid => 1,version => 'HTTP/1.1'}, {context,{user,<<"guest">>,
[administrator],
[{rabbit_auth_backend_internal,none}]},
<<"guest">>,undefined})
Recon tracer rate limit tripped.
El fragmento anterior muestra que primero habilitamos el seguimiento para
rabbit_mgmt_wm_queues:to_json/2
, luego enviamos manualmente una solicitud a la API de administración (usando curl; no visible en el fragmento) y que generó el evento de seguimiento. Así es como encontramos nuestro punto de entrada para un análisis más profundo.
Usando flame graphs
Una vez que hemos encontrado una función que sirve las solicitudes, ahora podemos verificar cómo esa función pasa su tiempo de ejecución. La técnica ideal para hacer esto es Flame Graphs. Una de sus definiciones establece que:
Los gráficos de llamas son una visualización del software perfilado, lo que permite identificar rápidamente y con precisión los caminos de código más frecuentes.
En nuestro caso, podríamos usar gráficos de llamas para visualizar la pila de llamadas de la función o, en otras palabras, qué funciones se llaman dentro de una función rastreada y cuánto tiempo tarda (en relación con el tiempo de ejecución de la función rastreada) para que estas funciones se ejecuten. Esta visualización ayuda a identificar rápidamente las funciones sospechosas en el código.
Para Erlang, existe una biblioteca llamada eflame que tiene herramientas tanto para: recopilar trazas del sistema Erlang como para construir un gráfico de llamas a partir de los datos. ¿Pero cómo inyectamos esa biblioteca en Rabbit para nuestra prueba de carga?
Construyendo una imagen personalizada de Docker para RabbitMQ
Como mencionamos anteriormente, todos los servicios de nuestra plataforma de pruebas de carga se ejecutan dentro de contenedores Docker. Por lo tanto, tuvimos que construir una imagen personalizada de Docker para RabbitMQ con la biblioteca eflame incluida en el código del servidor. Creamos un repositorio de RabbitMQ-docker que hace que sea fácil construir una imagen de Docker con el código fuente de RabbitMQ modificado.
Perfilando con eflame
Una vez que tuvimos una imagen de Docker de RabbitMQ modificada con eflame incluido, pudimos ejecutar otra prueba de carga (las especificaciones eran las mismas que en la prueba anterior) y comenzar el perfilado real. Estos fueron los resultados:
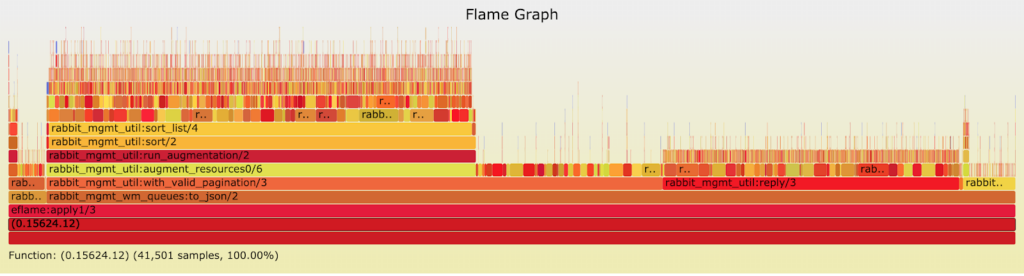
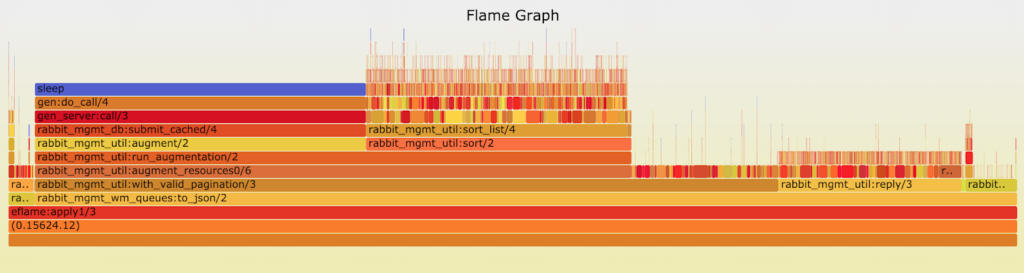
Realizamos varias mediciones y obtuvimos dos tipos de resultados como se presentan arriba. La principal diferencia entre estos gráficos se encuentra en la función
rabbit_mgmt_util:run_run_augmentation/2
. ¿Qué significa esa diferencia?
A partir de los resultados de las pruebas de carga anteriores y del análisis manual del código, sabemos que existen consultas lentas y rápidas. Las solicitudes lentas pueden tardar hasta veinte segundos, mientras que las rápidas solo tardan unos pocos segundos. Esto confirma el gráfico de tiempo de consulta anterior con un percentil del 50 de alrededor de 1,5 segundos, pero el 95 (y porcentajes más altos) que llegan hasta 20 segundos. Además, medimos manualmente el tiempo de ejecución de ambos casos utilizando timer:tc/3 y los resultados fueron consistentes.
Esto sucede porque hay una caché en el plugin de Management. Cuando la caché es válida, las solicitudes se sirven mucho más rápido ya que los datos ya se han recopilado, pero cuando es inválida, es necesario recopilar toda la información necesaria.
A pesar de que los gráficos tienen la misma longitud en la imagen, representan diferentes tiempos de ejecución (rápido vs lento). Por lo tanto, es difícil adivinar qué gráfico muestra qué consulta sin tomar realmente una medición. El primer gráfico muestra una consulta rápida mientras que el segundo muestra una consulta lenta. En el gráfico de consulta lenta
rabbit_mgmt_util:augment/2 -> rabbit_mgmt_db:submit_cached/4 -> gen_server:call/3 ->
… la pila tarda tanto tiempo porque la caché es inválida y se necesita recopilar datos nuevos. Entonces, ¿qué sucede cuando se recopilan los datos?
Perfiles con fprof
Podrías preguntar: “¿por qué no vemos las funciones de recopilación de datos en los gráficos de llama?” Esto sucede porque la caché se implementa como otro proceso de Erlang y la recopilación de datos ocurre dentro del proceso de caché. Hay una función
gen_server:call/3
visible en los gráficos que hace una llamada al proceso de caché y espera una respuesta. Dependiendo del estado de la caché (válido o inválido), una respuesta puede volver rápidamente o lentamente.
La recopilación de datos se implementa en la función rabbit_mgmt_db:list_queue_stats/3 que se invoca desde el proceso de caché. Naturalmente, deberíamos perfilar esa función. Probamos con eflame y después de varias docenas de minutos , este es el resultado que obtuvimos:
eheap_alloc: Cannot allocate 42116020480 bytes of memory (of type "old_heap").
El asignador de memoria del montón de Erlang intentó asignar 42 GB de memoria (de hecho, se necesitaba espacio para que el recolector de basura operara) y se bloqueó el servidor. Como eflame aprovecha el seguimiento de Erlang para generar gráficos de llama, probablemente se sobrecargó con la cantidad de eventos de seguimiento generados por la función rastreada. Ahí es donde entra en juego fprof.
Según la documentación oficial de Erlang, fprof es:
una herramienta de perfilado de tiempo que utiliza el seguimiento de archivo para un impacto mínimo en el rendimiento en tiempo de ejecución.
Esto es muy cierto. La herramienta manejó la función de recopilación de datos sin problemas, aunque tardó varios minutos en producir el resultado. La salida fue bastante grande, así que solo se enumeran las líneas cruciales a continuación:
(rabbit@rmq-test-rabbitmq-1)96> fprof:apply(rabbit_mgmt_db, list_queue_stats, [RA, B, 5000]).
...
(rabbit@rmq-test-rabbitmq-1)97> fprof:profile().
...
(rabbit@rmq-test-rabbitmq-1)98> fprof:analyse().
...
% CNT ACC OWN
{[{{rabbit_mgmt_db,'-list_queue_stats/3-lc$^1/1-1-',4}, 803,391175.593, 105.666}],
{ {rabbit_mgmt_db,queue_stats,3}, 803,391175.593, 105.666}, %
[{{rabbit_mgmt_db,format_range,4}, 3212,390985.427, 76.758},
{{rabbit_mgmt_db,pick_range,2}, 3212, 58.047, 34.206},
{{erlang,'++',2}, 2407, 19.445, 19.445},
{{rabbit_mgmt_db,message_stats,1}, 803, 7.040, 7.040}]}.
El resultado consiste en muchas de estas entradas. La función marcada con el carácter % es la que concierne a la entrada actual. Las funciones que se encuentran debajo son las que se llamaron desde la función marcada. La tercera columna (
ACC
) muestra el tiempo de ejecución total de la función marcada (tiempo de ejecución propio de la función y de los que la llaman) en milisegundos. Por ejemplo, en la entrada anterior, el tiempo de ejecución total de la función
rabbit_mgmt_db:pick_range/2
es de 58.047 ms. Para obtener una explicación detallada de la salida de fprof, consulte la documentación oficial de fprof.
La entrada anterior es la entrada de nivel superior que concierne a
rabbit_mgmt_db:queue_stats/3
, que se llamó desde la función rastreada. Esa función gastó la mayor parte de su tiempo de ejecución en la función
rabbit_mgmt_db:format_range/4.
Podemos ir a una entrada que concierna a esa función y comprobar en qué gastó su tiempo de ejecución. De esta manera, podemos revisar la salida y encontrar posibles causas del problema de lentitud de la API de gestión.
Al leer la salida de fprof de arriba hacia abajo, llegamos a esta entrada:
{[{{exometer_slide,'-sum/5-anonymous-6-',7}, 3713,364774.737, 206.874}],
{ {exometer_slide,to_normalized_list,6}, 3713,364774.737, 206.874}, %
[{{exometer_slide,create_normalized_lookup,4},3713,213922.287, 64.599}, %% SUSPICIOUS
{{exometer_slide,'-to_normalized_list/6-lists^foldl/2-4-',3},3713,145165.626, 51.991}, %% SUSPICIOUS
{{exometer_slide,to_list_from,3}, 3713, 4518.772, 201.682},
{{lists,seq,3}, 3713, 837.788, 35.720},
{{erlang,'++',2}, 3712, 70.038, 70.038},
{{exometer_slide,'-sum/5-anonymous-5-',1}, 3713, 51.971, 25.739},
{garbage_collect, 1, 1.269, 1.269},
{suspend, 2, 0.151, 0.000}]}.
La entrada se refiere a la función
exometer_slide:to_normalized_list/6
que a su vez llamó a dos funciones “sospechosas” del mismo módulo. Profundizando encontramos esto:
{[{{exometer_slide,'-create_normalized_lookup/4-anonymous-2-',5},347962,196916.209,35453.182},
{{exometer_slide,'-sum/5-anonymous-4-',2}, 356109,16625.240, 4471.993},
{{orddict,update,4}, 20268881, 0.000,172352.980}],
{ {orddict,update,4}, 20972952,213541.449,212278.155}, %
[{suspend, 9301, 682.033, 0.000},
{{exometer_slide,'-sum/5-anonymous-3-',2}, 31204, 420.574, 227.727},
{garbage_collect, 99, 160.687, 160.687},
{{orddict,update,4}, 20268881, 0.000,172352.980}]}.
and
{[{{exometer_slide,'-to_normalized_list/6-anonymous-5-',3},456669,133229.862, 3043.145},
{{orddict,find,2}, 19369215, 0.000,129761.708}],
{ {orddict,find,2}, 19825884,133229.862,132804.853}, %
[{suspend, 4754, 392.064, 0.000},
{garbage_collect, 22, 33.195, 33.195},
{{orddict,find,2}, 19369215, 0.000,129761.708}]}.
Gran parte del tiempo de ejecución fue consumido por las funciones
orddict:update/4
y
orddict:find/2
. Ambas funciones combinadas representaron el
86%
del tiempo total de ejecución.
Esto nos llevó al módulo exometer_slide del plugin RabbitMQ Management Agent. Si se examina el módulo, se encontrarán todas las funciones mencionadas y las conexiones entre ellas.
Decidimos cerrar la investigación en esta etapa porque este era claramente el problema. Ahora que hemos compartido nuestras reflexiones sobre el problema con la comunidad en este blog, quién sabe, tal vez encontraremos una nueva solución juntos.
El efecto observador
Hay una última cosa que es esencial considerar cuando se trata de depurar/observar sistemas: el efecto observador. El efecto observador es una teoría que afirma que si estamos monitoreando algún tipo de fenómeno, el proceso de observación cambia ese fenómeno.
En nuestro ejemplo, utilizamos herramientas que se aprovechan del rastreo. El rastreo tiene un impacto en un sistema ya que genera, envía y procesa muchos eventos.
Los tiempos de ejecución de las funciones mencionadas anteriormente aumentaron considerablemente cuando se llamaron con el perfilado habilitado. Las llamadas puras tomaron varios segundos mientras que las llamadas con el perfilado habilitado tomaron varios minutos. Sin embargo, la diferencia entre las consultas lentas y rápidas pareció permanecer sin cambios.
El efecto observador no fue evaluado en el alcance del experimento descrito en esta publicación de blog.
Una solución alternativa
El problema puede ser resuelto de una manera ligeramente diferente. Pensemos por un momento si hay otra manera de obtener los nombres de las colas correspondientes a la cantidad de mensajes en ellas. Existe la función rabbit_amqqueue:emit_info_all/5 que nos permite recuperar la información exacta que nos interesa, directamente desde un proceso de cola. Podríamos utilizar esa API desde un plugin personalizado de RabbitMQ y exponer un punto final HTTP para enviar esos datos cuando se consulten.
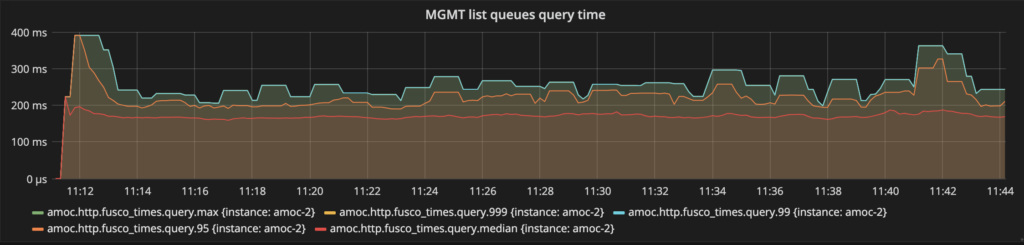
Convertimos esa idea en realidad y construimos un plugin de prueba de concepto llamado rabbitmq-queue-info que hace exactamente lo que se describe arriba. Incluso se realizó una prueba de carga del plugin (la especificación de la prueba fue exactamente la misma que la del plugin de gestión, como se mencionó anteriormente en el blog). Los resultados se muestran a continuación y hablan por sí solos:
¿Quieren más?
¿Quiere saber más sobre el rastreo en RabbitMQ, Erlang y Elixir? Consulte WombatOAM, un sistema intuitivo que facilita la supervisión y el mantenimiento de sus sistemas. Obtenga su prueba gratuita de 45 días de WombatOAM ahora.
Apéndice
La versión 3.7.9 de RabbitMQ se utilizó en todas las pruebas de carga mencionadas en esta publicación de blog. Un agradecimiento especial a Szymon Mentel y Andrzej Teleżyński por toda la ayuda con esa publicación.
The post Cómo depurar tu RabbitMQ appeared first on Erlang Solutions .
 Text from the image:(Streams: a un nuevo tipo de estructura de datos en RabbitMQ)
Text from the image:(Streams: a un nuevo tipo de estructura de datos en RabbitMQ)
 Text from the image:(Grandes fan-outs) (Repetición/tiempo de viaje)(Alto rendimiento)(Grandes registros)
Text from the image:(Grandes fan-outs) (Repetición/tiempo de viaje)(Alto rendimiento)(Grandes registros)
 Text from the image:
Text from the image:
 Text from the image:
Text from the image:
 Text from the image: (Protocolo Stream)
Text from the image: (Protocolo Stream)
 Text from the image: (Los Streams son también accesibles a través de un nuevo protocolo)
Text from the image: (Los Streams son también accesibles a través de un nuevo protocolo)
 Text from the image: (Agregar Stream para Analiticas)
Text from the image: (Agregar Stream para Analiticas)
 Text from the image: (Garantías) (Mensajes de deduplicación) (Control de flujo)
Text from the image: (Garantías) (Mensajes de deduplicación) (Control de flujo)
 Text from the image: (Streams: una nueva estructura de tipo de registro replicada y persistente en RabbitMQ)
Text from the image: (Streams: una nueva estructura de tipo de registro replicada y persistente en RabbitMQ)
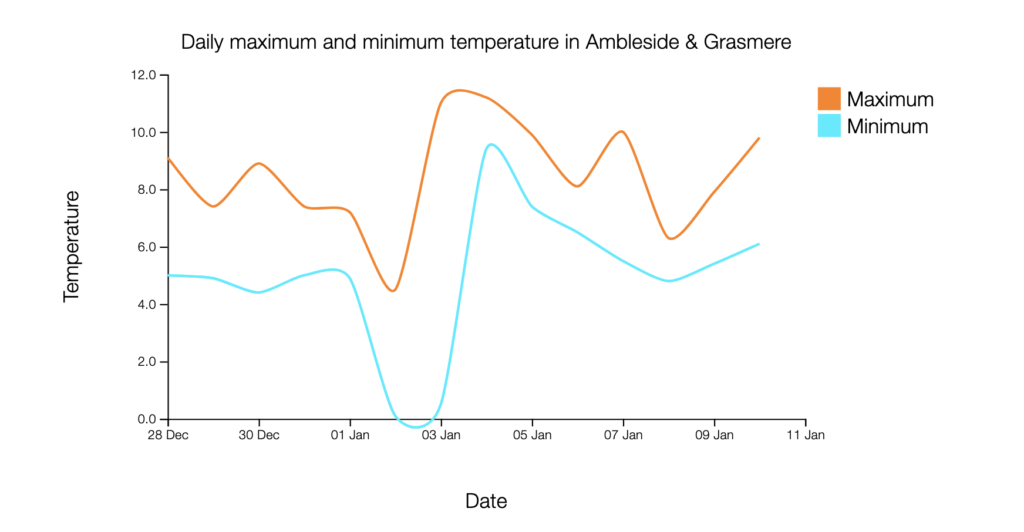 The graph generated by Contex
The graph generated by Contex
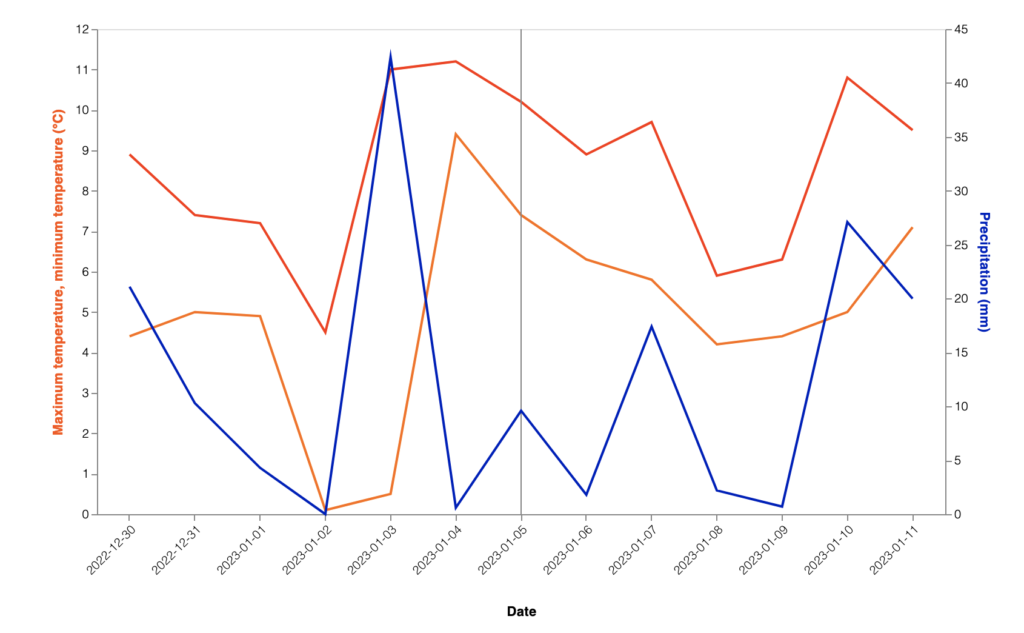 |The graph generated by Contex
|The graph generated by Contex







