In the realm of technology, speed isn’t merely a single factor; it’s a constant way of life. Developers frequently find themselves needing to rethink solutions overnight, underscoring the importance of being able to swiftly modify code. This agility has become indispensable in modern development, especially when evaluating the fastest programming language.
Because of this, finding the right language is a recurring obstacle for both developers and business owners. Regardless of your use case,
Elixir consulting
can be one proven way to harness one of the fastest programming language options available today.
But defining what “the fastest programming language” means in the context of development can be just as complicated. To better understand adaptability and speed in coding languages, we’ve outlined how this should be determined, alongside some of the leading trends that continue to disrupt the concept of fast programming at present.
What determines a programming language’s speed?
Several factors go into determining which programming language is the fastest. It’s first important to note that the quality of your code, and the skill of the programmer behind it, matters more than the specific language you’re using. This is why it’s crucial to work with talented, experienced developers well-versed in their respective languages.
However, there are factors which impact how efficiently a code can be implemented. One example is multi-threading, or concurrency.
Concurrency means
you’re able to perform multiple complicated tasks at once; languages with this capacity are therefore often more versatile, and faster, as a result.
Another core way in which languages differ in terms of speed is whether they’re compiled or interpreted languages.
Compiled vs interpreted languages
All programming languages are written in human-readable code and then translated into machine-readable code so they can be executed. The way this information transfer occurs can however have a big impact on both flexibility and speed.
Interpreted languages are read through an interpreter which then translates the code. Conversely, compiled languages allow the machine to directly understand code without an interpreter.
A simplified way of thinking about this is to see interpreted languages as a conversation between two people who speak different languages, with an interpreter translating between them. Meanwhile, compiled languages are more like a conversation between two people who speak the same language.
In practice, this means compiled languages can be executed faster than interpreted languages because they don’t require a translation step.
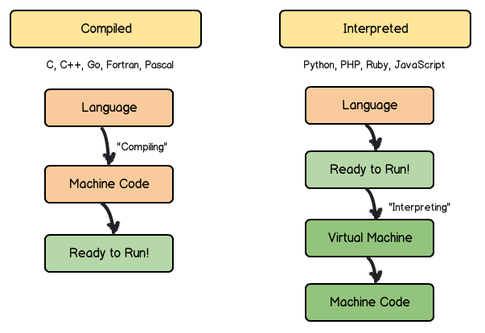
Compiled v interpreted language
It also means programmers can be more flexible when using compiled languages, as they have more control over areas like CPU usage.
Is Elixir one of the fastest programming language options?
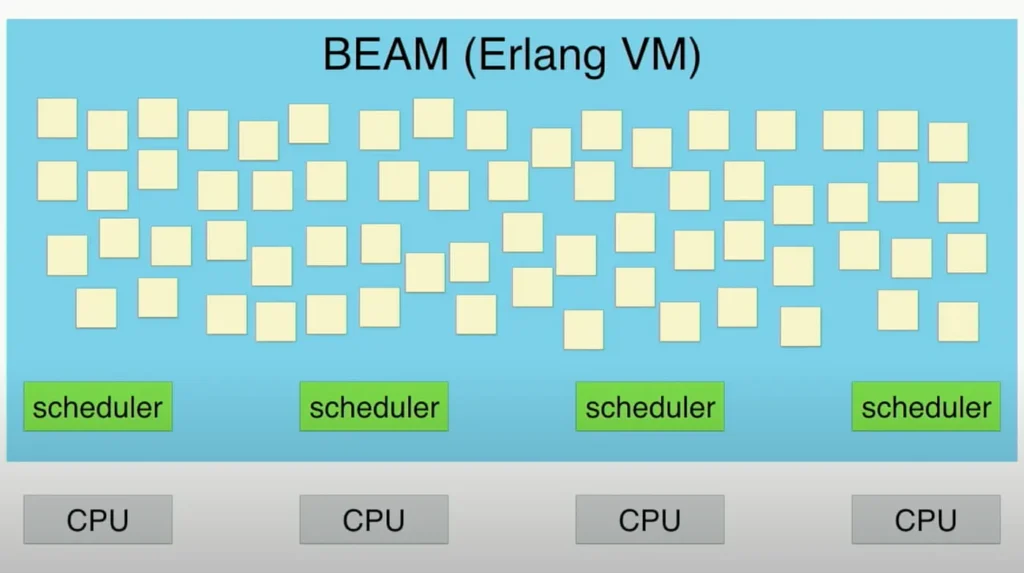
Elixir is a compiled language, which means it has several efficiency benefits when compared with interpreted languages like Python and JavaScript, among others.
Elixir programming
is also a process that was initially designed with concurrency in mind. This means programmers can easily use multi-threading, allowing them to build complex solutions more effectively. Elixir’s benefits also extend to fault tolerance; whilst not directly improving speed, the ability to keep systems functional makes solutions more reliable and allows developers to solve problems in a targeted way.
When combining these features with Elixir’s scalability, it becomes one of the fastest programming language options available to developers today.
Top contenders for the fastest programming language
In the present day, a plethora of programming languages are available for use, with developers continually innovating and introducing new ones. The effectiveness of a programming language often hinges on its design, usability, efficiency, and applicability.
It’s essential to grasp the factors influencing the performance of a programming language. Parameters such as execution speed, memory utilisation, and adeptness in managing intricate tasks are pivotal considerations for developers assessing language proficiency.
That said, let’s delve into the contenders.
Python: versatility and speed
Python is a widely used programming language that is great for building highly scalable websites for users:

Readability and simplicity:
Python boasts a syntax engineered for readability and ease of comprehension, prioritisng code clarity and maintainability. Its straightforward and intuitive structure allows developers to articulate concepts concisely.
Abundant libraries and frameworks:
Python boasts a rich ecosystem of libraries and frameworks that streamline various web development tasks.
Thriving community:
Backed by a thriving and expansive community of developers, Python experiences continual growth and support.
Scalability and performance:
Python garners acclaim for its scalability and performance, allowing it to manage high-volume web applications.
Integration and compatibility:
Python seamlessly integrates with various technologies, affording flexibility in web development endeavours.
Swift: the speed of Apple’s innovation
Swift in mobile app development
Central to iOS app development is Swift, Apple’s robust and user-friendly programming language. The goal of Swift app development was simplification. Swift’s succinct and expressive syntax empowers developers to craft code that is both cleaner and easier to maintain.
The main drivers behind its increasing popularity are:
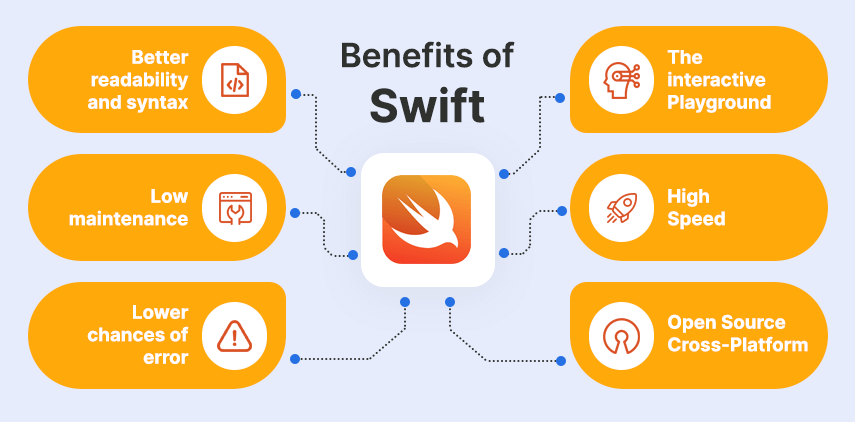
Benefits of SWIFT Language for iOS Development
Enhanced syntax and readability:
Swift boasts a concise syntax, making it easy to understand and work with.
Reduced maintenance:
Swift streamlines the coding process and operates independently of other programming databases, leading to high efficiency.
Minimised error probability:
With Swift, the likelihood of coding or compiling errors is significantly decreased. It emphasizes safety and security.
Interactive playground:
The Swift Playground feature enables developers to experiment with coding algorithms without having to complete the entire app, enhancing creativity and coding speed.
High performance:
Swift excels in speed compared to other programming languages, resulting in lower developmental costs.
Open source:
Swift is freely available and allows for extensive customisation based on individual needs.
Ruby: Quick development and easy syntax
Ruby on Rails for web applications
Ruby on Rails (or Rails) is known for its capacity to streamline web development, Rails emphasises efficiency, enabling developers to achieve more with less code compared to many other frameworks.
Building apps quickly and easily:
Rails focuses on quick prototyping and iterative development. This approach minimises bugs, enhances adaptability, and makes the Rails application code more intuitive.
Open-source libraries:
Ruby on Rails has plenty of ready-made libraries available. These libraries enable you to enhance your web application without starting from scratch. The supportive Rails community often improves these tools, making them more accessible and valuable, with ample community support on platforms like GitHub.
Simple Model View Controller (MVC):
Long-time fans of Ruby on Rails swear by the MVC architecture. Thanks to MVC, it’s incredibly time-efficient for Rails developers to create and maintain web applications.
Reliable testing environment:
Rails applications come with three default environments: production, development, and test. These environments are defined in a simple configuration file. Having separate tests and data for testing ensures that it won’t interfere with the actual development or production database.
Flexible code modification and migration:
Ruby on Rails has flexibility in modifying and migrating code. Migration allows you to define changes in your database structure, making it possible to use a version control system to keep things in sync. This flexibility is great for scalability and cost-effectiveness because you don’t have to overhaul your source code when migrating to another platform.
Kotlin: a modern approach to speed
Kotlin in Android development
Kotlin is a versatile programming language that works on various platforms. It meets Android app development requirements, especially since it’s a supported language for crafting Android app code.

Kotlin: The official programming language for Android
Streamlined Android app development:
Kotlin presents a more efficient approach to creating Android apps, with a compact library that keeps method counts low.
Simplified code and enhanced readability:
Kotlin shortens code and improves readability, reducing errors and expediting coding processes.
Open-source advantage:
Being open-source ensures consistent support from the Kotlin Slack team, fostering high-quality development.
Ease of learning:
Kotlin proves to be a user-friendly language for beginners, with easily understandable code that empowers developers to solve problems creatively and effectively.
Increased productivity and accelerated development:
Adopting Kotlin leads to heightened productivity and faster development. Safety features like null safety reduce bug occurrences, resulting in quicker debugging and maintenance.
Java: A balanced blend of speed and functionality
Java in enterprise solutions
Java’s “write once, run anywhere” capability makes it a top choice for enterprise software development, offering extensive support across diverse platforms and operating systems.
This feature enables developers to write code once and execute it across various environments, resulting in significant time and cost savings while minimizing maintenance requirements. In the realm of IT, Java’s cross-platform compatibility ensures seamless operation across platforms like Windows, Mac OS, and Linux, making it particularly well-suited for enterprise needs.
Security:
Paramount in enterprise applications, and Java’s architecture offers robust security features to protect both data and applications, ensuring the integrity of business operations.
Multithreading:
Java’s multithreaded environment enhances performance by enabling faster response times, smoother operations, and efficient management of multiple requests simultaneously. This not only boosts productivity but also reduces development challenges for enterprise applications handling numerous threads.
Simplicity to use:
The simplicity and flexibility of Java coding, coupled with its user-friendly interface, streamline the development process. Additionally, Java’s reusable code promotes efficiency, allowing enterprises to leverage existing codebases for developing new software applications while ensuring ease of maintenance.
Stability:
Renowned for its stability, Java stands as one of the most reliable programming languages, capable of managing errors without compromising the entire application. This stability fosters trust among companies seeking a dependable language to deliver a seamless customer experience.
Availability of libraries:
Java’s vast library support empowers developers with a plethora of resources to address various challenges and fulfil specific functionalities, further enhancing its appeal for enterprise development projects.
Comparing speeds: fastest languages programming
From powering high-performance applications to ensuring swift response times in web services, the programming language used can significantly impact the efficiency and effectiveness of a project. In this exploration of programming languages. Let’s uncover the strengths and capabilities of each language in delivering optimal performance across diverse domains.
C++: the powerhouse of performance
C++ in game and system development
In gaming, where milliseconds matter, C++ allows developers to fine-tune performance for smooth gameplay and stunning graphics. Similarly, in system programming tasks like operating system development, C++’s speed and efficiency ensure responsiveness and reliability.
C#: versatility in the .NET framework
C# in desktop and web services
C# shines in desktop and web service development, offering a balance of speed and versatility within the .NET framework.
While not as low-level as C++, it excels in building responsive desktop applications and powerful web services. With features like just-in-time compilation and memory management, C# enables developers to create applications that perform well and scale seamlessly, whether on the desktop or in the cloud.
Lesser-known speed demons
Exploring languages like Assembly, Lisp, and Go
Beyond the mainstream languages, there are lesser-known options that excel in terms of speed. Assembly, known for its direct hardware manipulation, is a go-to choice for projects requiring maximum performance, such as embedded systems and real-time applications. Lisp, with its powerful macro system, allows developers to optimise code for specific tasks, resulting in highly efficient programs. Go, a relatively newer language, offers simplicity and built-in concurrency features, making it ideal for tasks demanding speed and scalability.
JavaScript and PHP: Dominating the web
Scripting languages in web development
JavaScript and PHP have become foundational in web development, powering a vast majority of websites and web applications. Despite their scripting nature, they have evolved to deliver impressive speed and performance, driving innovation on the web. JavaScript’s advancements in browser technology, including just-in-time compilation, have elevated its performance to near-native levels, enabling the creation of complex client-side applications. Similarly, PHP has evolved into a robust platform for server-side web development, with features like opcode caching and asynchronous processing enhancing its speed and scalability. Together, JavaScript and PHP form the backbone of the web, enabling dynamic and interactive experiences for users worldwide.
The future of fast programming
As with all facets of technology, the nature of fast programming is evolving every day. Several trends and innovations are set to transform the concept of efficiency in programming in the coming months.
Emerging trends in programming speed
Compiled languages remain more efficient than interpreted languages in general, but this gap is steadily closing. This is thanks to what’s known as
“just-in-time compilation
”, also known as dynamic compilation, which is a method designed to improve efficiency in interpreted languages.
Open source development is another important trend when considering how the fastest programming language argument will evolve. These are situations where code is made freely available to everyone so that developers can learn collaboratively. Open source plays a key role in improving programming speeds across the industry, as it means all developers have access to new methods that can be studied and standardised. Languages with larger open source communities may therefore become more efficient over time.
Both low-code and no-code programming have also become more prominent in recent years. These approaches are no substitute for fully coded applications created by experienced developers, but they do evidence the continued focus on speed and efficiency gains in software development today.
Innovations and future predictions
At the moment,
AI’s role in programming
is mostly speculative. But as the technology evolves, both AI and machine learning may further disrupt the efficiency potential of programming languages.
One common prediction is for AI to be able to automate some of the more repetitive coding tasks, by analysing coding patterns and then generating short lines of code. In theory, this will reduce the time programmers spend on repetitive tasks, allowing them to experiment and focus on more detailed parts of programming. AI simply isn’t reliable enough to provide this level of support across the profession yet, but that may change in the coming years.
Speed in programming isn’t simply about developing initial builds quickly, it also concerns the ability to scale at speed. Scalability potential in programming languages will therefore continue to play a pivotal role in their selection for advanced systems in the future.
Finally, coding practices designed to streamline and automate the process of programming, like implementing CLIs (command-line interpreters), will continue to play a role in programming speed gains. Being versatile is already a key part of a programmer’s job description, but being able to write
efficient, lean code
will likely grow in importance as speed and scalability both remain core priorities.
Choosing the fastest programming language for your needs
Determining which programming language is the fastest is dependent on your individual use case. If you’re looking to create a web solution, for example, you’d need to be specifically looking for the fastest web programming language.
If you’re working with complex, distributed systems that need a high level of fault tolerance and the ability to scale, Elixir is the ideal language to work with. Find out more about its efficiency potential on
our Elixir page
, or by
contacting our team directly.
The post
What Is the Fastest Programming Language? Making the Case for Elixir
appeared first on
Erlang Solutions
.


 chevron_right
chevron_right