-
Pl
chevron_right
Christian Schaller: Using AI to create some hardware tools and bring back the past
news.movim.eu / PlanetGnome • 23 March 2026 • 18 minutes
As I talked about in a couple of blog posts now I been working a lot with AI recently as part of my day to day job at Red Hat, but also spending a lot of evenings and weekend time on this (sorry kids pappa has switched to 1950’s mode for now). One of the things I spent time on is trying to figure out what the limitations of AI models are and what kind of use they can have for Open Source developers.
One thing to mention before I start talking about some of my concrete efforts is that I more and more come to conclude that AI is an incredible tool to hypercharge someone in their work, but I feel it tend to fall short for fully autonomous systems. In my experiments AI can do things many many times faster than you ordinarily could, talking specifically in the context of coding here which is what is most relevant for those of us in the open source community.
So one annoyance I had for years as a Linux user is that I get new hardware which has features that are not easily available to me as a Linux user. So I have tried using AI to create such applications for some of my hardware which includes an Elgato Light and a Dell Ultrasharp Webcam.
I found with AI and this is based on using Google Gemini, Claude Sonnet and Opus and OpenAI codex, they all required me to direct and steer the AI continuously, if I let the AI just work on its own, more often than not it would end up going in circles or diverging from the route it was supposed to go, or taking shortcuts that makes wanted output useless.On the other hand if I kept on top of the AI and intervened and pointed it in the right direction it could put together things for me in very short time spans.
My projects are also mostly what I would describe as end leaf nodes, the kind of projects that already are 1 person projects in the community for the most part. There are extra considerations when contributing to bigger efforts, and I think a point I seen made by others in the community too is that you need to own the patches you submit, meaning that even if an AI helped your write the patch you still need to ensure that what you submit is in a state where it can be helpful and is merge-able. I know that some people feel that means you need be capable of reviewing the proposed patch and ensuring its clean and nice before submitting it, and I agree that if you expect your patch to get merged that has to be the case. On the other hand I don’t think AI patches are useless even if you are not able to validate them beyond ‘does it fix my issue’.
My friend and PipeWire maintainer Wim Taymans and I was talking a few years ago about what I described at the time as the problem of ‘bad quality patches’, and this was long before AI generated code was a thing. Wim response to me which I often thought about afterwards was “a bad patch is often a great bug report”. And that would hold true for AI generated patches to. If someone makes a patch using AI, a patch they don’t have the ability to code review themselves, but they test it and it fixes their problem, it might be a good bug report and function as a clearer bug report than just a written description by the user submitting the report. Of course they should be clear in their bug report that they don’t have the skills to review the patch themselves, but that they hope it can be useful as a tool for pinpointing what isn’t working in the current codebase.
Anyway, let me talk about the projects I made. They are all found on my personal website Linuxrising.org a website that I also used AI to update after not having touched the site in years.
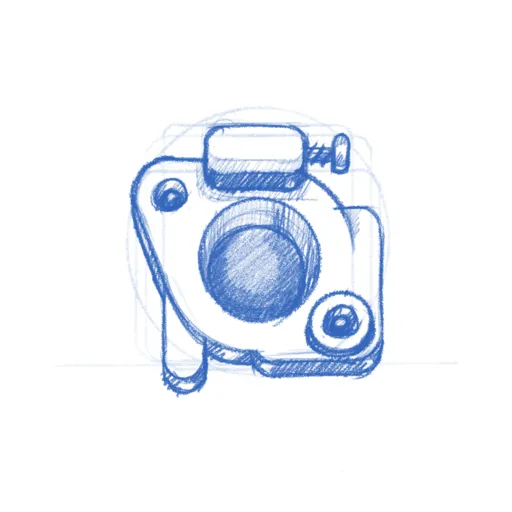
Elgato Light GNOME Shell extension

Elgato Light GNOME Shell extension
The first project I worked on is a GNOME Shell extension for controlling my Elgato Key Wifi Lamp . The Elgato lamp is basically meant for podcasters and people doing a lot of video calls to be able to easily configure light in their room to make a good recording. The lamp announces itself over mDNS, and thus can be controlled via Avahi. For Windows and Mac the vendor provides software to control their lamp, but unfortunately not for Linux.
There had been GNOME Shell extensions for controlling the lamp in the past, but they had not been kept up to date and their feature set was quite limited. Anyway, I grabbed one of these old extensions and told Claude to update it for latest version of GNOME. It took a few iterations of testing, but we eventually got there and I had a simple GNOME Shell extension that could turn the lamp off and on and adjust hue and brightness. This was a quite straightforward process because I had code that had been working at some point, it just needed some adjustments to work with current generation of GNOME Shell.
Once I had the basic version done I decided to take it a bit further and try to recreate the configuration dialog that the windows application offers for the full feature set which took me quite a bit of back and forth with Claude. I found that if I ask Claude to re-implement from a screenshot it recreates the functionality of the user interface first, meaning that it makes sure that if the screenshot has 10 buttons, then you get a GUI with 10 buttons. You then have to iterate both on the UI design, for example telling Claude that I want a dark UI style to match the GNOME Shell, and then I also had to iterate on each bit of functionality in the UI. Like most of the buttons in the UI didn’t really do anything from the start, but when you go back and ask Claude to add specific functionality per button it is usually able to do so.

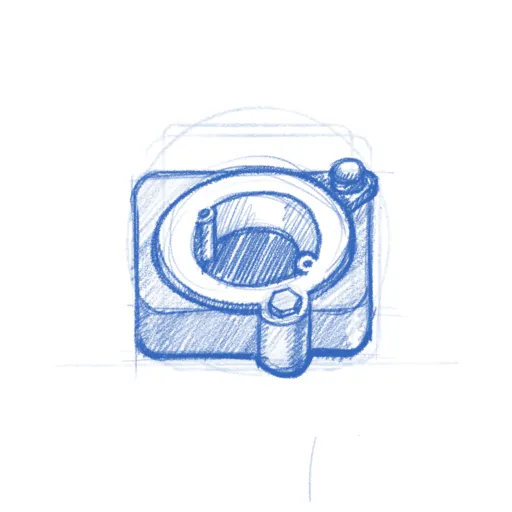
Elgato Light Settings Application
So this was probably a fairly easy thing for the AI because all the functionality of the lamp could be queried over Avahi, there was no ‘secret’ USB registers to be set or things like that.
Since the application was meant to be part of the GNOME Shell extension I didn’t want to to have any dependency requirements that the Shell extension itself didn’t have, so I asked Claude to make this application in JavaScript and I have to say so far I haven’t seen any major differences in terms of the AIs ability to generate different languages. The application now reproduce most of the functionality of the Windows application. Looking back I think it probably took me a couple of days in total putting this tool together.

Dell UltraSharp 4K settings application for Linux
The second application on the list is a controller application for my Dell UltraSharp Webcam 4K UHD (WB7022) . This is a high end Webcam I that have been using for a while and it is comparable to something like the Logitech BRIO 4K webcam. It has mostly worked since I got it with the generic UVC driver and I been using it for my Google Meetings and similar, but since there was no native Linux control application I could not easily access a lot of the cameras features. To address this I downloaded the windows application installer and installed it under Windows and then took a bunch of screenshots showcasing all features of the application. I then fed the screenshots into Claude and told it I wanted a GTK+ version for Linux of this application. I originally wanted to have Claude write it in Rust, but after hitting some issues in the PipeWire Rust bindings I decided to just use C instead.
I took me probably 3-4 days with intermittent work to get this application working and Claude turned out to be really good and digging into Windows binaries and finding things like USB property values. Claude was also able to analyze the screenshots and figure out the features the application needed to have. It was a lot of trial and error writing the application, but one way I was able to automate it was by building a screenshot option into the application, allowing it to programmatically take screenshots of itself. That allowed me to tell Claude to try fixing something and then check the screenshot to see if it worked without me having to interact with the prompt. Also to get the user interface looking nicer, once I had all the functionality in I asked Claude to tweak the user interface to follow the guidelines of the GNOME Human Interface Guidelines, which greatly improved the quality of the UI.
At this point my application should have almost all the features of the Windows application. Since it is using PipeWire underneath it is also tightly integrated with the PipeWire media graph, allowing you to see it connect and work with your application in PipeWire patchbay applications like Helvum. The remaining features are software features of Dell’s application, like background removal and so on, but I think that if I decided to to implement that it should be as a standalone PipeWire tool that can be used with any camera, and not tied to this specific one.

The application shows the worlds Red Hat offices and include links to latest Red Hat news.
The next application on my list is called Red Hat Planet. It is mostly a fun toy, but I made it to partly revisit the Xtraceroute modernisation I blogged about earlier. So as I mentioned in that blog, Xtraceroute while cute isn’t really very useful IMHO, since the way the modern internet works rarely have your packets jump around the world. Anyway, as people pointed out after I posted about the port is that it wasn’t an actual Vulkan application, it was a GTK+ application using the GTK+ Vulkan backend. The Globe animation itself was all software rendered.
I decided if I was going to revisit the Vulkan problem I wanted to use a different application idea than traceroute. The idea I had was once again a 3D rendered globe, but this one reading the coordinates of Red Hats global offices from a file and rendering them on the globe. And alongside that provide clickable links to recent Red Hat news items. So once again maybe not the worlds most useful application, but I thought it was a cute idea and hopefully it would allow me to create it using actual Vulkan rendering this time.
Creating this turned out to be quite the challenge (although it seems to have gotten easier since I started this effort), with Claude Opus 4.6 being more capable at writing Vulkan code than Claude Sonnet, Google Gemini or OpenAI Codex was when I started trying to create this application.
When I started this project I had to keep extremely close tabs on the AI and what is was doing in order to force it to keep working on this as a Vulkan application, as it kept wanting to simplify with Software rendering or OpenGL and sometimes would start down that route without even asking me. That hasn’t happened more recently, so maybe that was a problem of AI of 5 Months ago.
I also discovered as part of this that rendering Vulkan inside a GTK4 application is far from trivial and would ideally need the GTK4 developers to create such a widget to get rendering timings and similar correct. It is one of the few times I have had Claude outright say that writing a widget like that was beyond its capabilities (haven’t tried again so I don’t know if I would get the same response today). So I started moving the application to SDL3 first, which worked as I got a spinning globe with red dots on, but came with its own issues, in the sense that SDL is not a UI toolkit as such. So while I got the globe rendered and working the AU struggled badly with the news area when using SDL.
So I ended up trying to port the application to Qt, which again turned out to be non-trivial in terms of how much time it took with trial and error to get it right. I think in my mind I had a working globe using Vulkan, how hard could it be to move it from SDL3 to Qt, but there was a million rendering issues. In fact I ended up using the Qt Vulkan rendering example as a starting point in the end and then ‘porting’ the globe over bit by bit, testing it for each step, to finally get a working version. The current version is a Vulkan+Qt app and it basically works, although it seems the planet is not spinning correctly on AMD systems at the moment, while it seems to work well on Intel and NVIDIA systems.

WmDock fullscreen with config application.
This project came out of a chat with Matthias Clasen over lunch where I mused about if Claude would be able to bring the old Window Maker dockapps to GNOME and Wayland. Turns out the answer is yes although the method of doing so changed as I worked on it.
My initial thought was for Claude to create a shim that the old dockapps could be compiled against, without any changes. That worked, but then I had a ton of dockapps showing up in things like the alt+tab menu. It also required me to restart my GNOME Shell session all the time as I was testing the extension to house the dockapps. In the end I decided that since a lot of the old dockapps don’t work with modern Linux versions anyway, and thus they would need to be actively ported, I should accept that I ship the dockapps with the tool and port them to work with modern linux technologies. This worked well and is what I currently have in the repo, I think the wildest port was porting the old dockapp webcam app from V4L1 to PipeWire. Although updating the soundcontroller from ESD to PulesAudio was also a generational jump.

XMMS brought back to life
So the last effort I did was reviving the old XMMS media player. I had tried asking Claude to do this for Months and it kept failing, but with Opus 4.6 it plowed through it and had something working in a couple of hours, with no input from me beyond kicking it off. This was a big lift,moving it from GTK2 and Esound, to GTK4, GStreamer and PipeWire. One thing I realized is that a challenge with bringing an old app back is that since keeping the themeable UI is a big part of this specific application adding new features is a little kludgy. Anyway I did set it up to be able to use network speakers through PipeWire and also you can import your Spotify playlists and play those, although you need to run the Spotify application in the background to be able to play sound on your local device.
Monkey Bubble

Monkey Bubble was a game created in the heyday of GNOME 2 and while I always thought it was a well made little game it had never been updated to never technologies. So I asked Claude to port it to GTK4 and use GStreamer for audio.This port was fairly straightforward with Claude having little problems with it. I also asked Claude to add highscores using the libmanette library and network game discovery with Avahi. So some nice little.improvements.
All the applications are available either as Flatpaks or Fedora RPMS, through the gitlab project page, so I hope people enjoy these applications and tools. And enoy the blasts from the past as much as I did.
Worries about Artifical Intelligence
When I speak to people both inside Red Hat and outside in the community I often come across negativity or even sometimes anger towards Artificial Intelligence in the coding space. And to be clear I to worry about where things could be heading and how it will affect my livelihood too, so I am not unsympathetic to those worries at all. I probably worry about these things at least a few times a day. At the same time I don’t think we can hide from or avoid this change, it is happening with or without us. We have to adapt to a world where this tool exists, just like our ancestors have adapted to jobs changing due to industrialization and science before. So do I worry about the future, yes I do. Do I worry about how I might personally get affected by this? yes, I do. Do I worry about how society might change for the worse due to this? yes, I do. But I also remind myself that I don’t know the future and that people have found ways to move forward before and society has survived and thrived. So what I can control is that I try to be on top of these changes myself and take advantage of them where I can and that is my recommendation to the wider open source community on this too. By leveraging them to move open source forward and at the same time trying to put our weight on the scale towards the best practices and policies around Artificial Intelligence.
The Next Test and where AI might have hit a limit for me.
So all these previous efforts did teach me a lot of tricks and helped me understand how I can work with an AI agent like Claude, but especially after the success with the webcam I decided to up the stakes and see if I could use Claude to help me create a driver for my Plustek OpticFilm 8200i scanner. So I have zero backround in any kind of driver development and probably less than zero in the field of scanner driver specifically. So I ended up going down a long row of deadends on this journey and I to this day has not been able to get a single scan out of the scanner with anything that even remotely resembles the images I am trying to scan.
My idea was to have Claude analyse the Windows and Mac driver and build me a SANE driver based on that, which turned out to be horribly naive and lead nowhere. One thing I realized is that I would need to capture USB traffic to help Claude contextualize some of the findings it had from looking at the Windows and Mac drivers.I started out with Wireshark and feeding Claude with the Wireshark capture logs. Claude quite soon concluded that the Wireshark logs wasn’t good enough and that I needed lower level traffic capture. Buying a USB packet analyzer isn’t cheap so I had the idea that I could use one of the ARM development boards floating around the house as a USB relay, allowing me to perfectly capture the USB traffic. With some work I did manage to set up my LibreComputer Solitude AML-S905D3-CC arm board going and setting it in device mode. I also had a usb-relay daemon going on the board. After a lot of back and forth, and even at one point trying to ask Claude to implement a missing feature in the USB kernel stack, I realized this would never work and I ended up ordering a Beagle USB 480 USB hardware analyzer.
At about the same time I came across the chipset documentation for the Genesys Logic GL845 chip in the scanner. I assumed that between my new USB analyzer and the chipset docs this would be easy going from here on, but so far no. I even had Claude decompile the windows driver using
ghidra
and then try to extract the needed information needed from the decompiled code.
I bought a network controlled electric outlet so that Claude can cycle the power of the scanner on its own.
So the problem here is that with zero scanner driver knowledge I don’t even know what I should be looking for, or where I should point Claude to, so I keept trying to brute force it by trial and error. I managed to make SANE detect the scanner and I managed to get motor and lamp control going, but that is about it. I can hear the scanner motor running and I ask for a scan, but I don’t know if it moves correctly. I can see light turning on and off inside the scanner, but I once again don’t know if it is happening at the correct times and correct durations. And Claude has of course no way of knowing either, relying on me to tell it if something seems like it has improved compared to how it was.
I have now used Claude to create two tools for Claude to use, once using a camera to detect what is happening with the light inside the scanner and the other recording sound trying to compare the sound this driver makes compared to the sounds coming out when doing a working scan with the MacOS X application. I don’t know if this will take me to the promised land eventually, but so far I consider my scanner driver attempt a giant failure. At the same time I do believe that if someone actually skilled in scanner driver development was doing this they could have guided Claude to do the right things and probably would have had a working driver by now.
So I don’t know if I hit the kind of thing that will always be hard for an AI to do, as it has to interact with things existing in the real world, or if newer versions of Claude, Gemini or Codex will suddenly get past a threshold and make this seem easy, but this is where things are at for me at the moment.




 Meson”
Meson”